
Zawartość
- Osiąganie celów wydajnościowych
- Cortex-A77 opiera się na mikroarchitekturze A76
- Wszystko razem dopasowane

Wraz z nowym procesorem graficznym Mali-G77 i procesorem wyświetlania Mali-D77, Arm zaprezentował swój najnowszy wysokowydajny procesor - Cortex-A77. Podobnie jak w przypadku zeszłorocznego Cortex-A76, Cortex-A77 został zaprojektowany z myślą o zastosowaniach premium, wymagających niskiego zużycia energii przez firmę Arm. Wszystko, od smartfonów po laptopy i całkiem prawdopodobne.
W przypadku Cortex-A77, Arm skupił się na maksymalnym zwiększeniu wydajności na cykl / zegar (IPC), którym mógłby zarządzać na Cortex-A76. Częstotliwości zegara, zużycie energii i obszar są zaprojektowane tak, aby pozostały w przybliżeniu w tym samym parku, ale nowy rdzeń może złamać więcej instrukcji naraz. Aby to zrobić, Arm zaprojektował jeszcze szerszy rdzeń niż w zeszłym roku i wprowadził szereg ulepszeń, aby rdzeń procesora był zasilany innymi sprawami. Zanim jednak do tego przejdziemy, przejrzyjmy ogólne omówienie i liczby wyników.
Osiąganie celów wydajnościowych
W sierpniu 2018 r. Arm nietypowo udostępnił mapę drogową procesora do 2020 r. Od Cortex-A73 w 2016 r. Do projektu „Hercules” w 2020 r. Firma obiecuje 2,5-krotny wzrost wydajności obliczeniowej. Spora część tej ogromnej projekcji została osiągnięta dzięki zasadniczej zmianie mikroarchitektury z użyciem Cortex-A76, wyższym nowoczesnym taktowaniu zegara oraz przesunięciu z 16 na 10, a teraz produkcji 7 nm z 5 nm, które mają nastąpić. W ubiegłym roku osiągnięto już około 1,8x korzyści z mapy drogowej, a Cortex-A77 zapewnia około 20 procentowy wzrost IPC. Dzięki temu jesteśmy na dobrej drodze do osiągnięcia celu 2,5-krotnego uzbrojenia, chociaż urządzenia mobilne o ograniczonym budżecie na energię i energię cieplną nie oczekują wszystkich tych korzyści.
Dla porównania, zeszłoroczny Cortex-A76 zapewnił około 30-35 procentowy wzrost w stosunku do Cortex-A75. W tym roku patrzymy na bardziej wyciszony, ale wciąż znaczący, 20-procentowy wzrost IPC między A77 i A76. To dobra wiadomość, ponieważ oznacza większą wydajność przy jednoczesnym zachowaniu podobnych ograniczeń cieplnych i mocy jak poprzednio. Kompromis polega na tym, że A77 jest około 17 procent większy niż A76, więc będzie kosztował nieco więcej pod względem powierzchni krzemu. Jeśli chcesz porównać z liderami komputerów stacjonarnych, AMD zarządzało 15-procentowym wzmocnieniem IPC między Zen2 i Zen +, podczas gdy IPC Intela pozostawało praktycznie niezmienne od lat.Oczywiście mówimy tutaj o różnych segmentach rynku, ale pokazuje to, jak zespół projektowy Arm odniósł imponujące zyski w ostatnich generacjach.
20% wzrost wydajności jest oferowany dla SoC opartych na Cortex-A77 nowej generacji
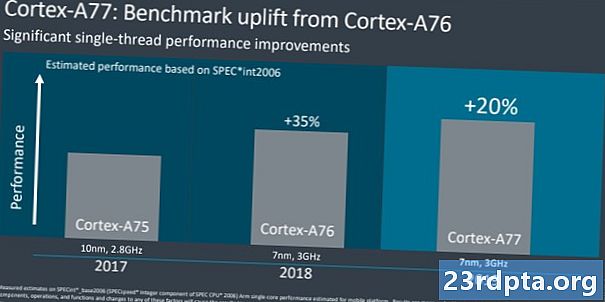
Zaletą jest to, że A76 oznaczał znaczną zmianę mikroarchitektoniczną z ogromnym wzrostem wydajności, podczas gdy wróciliśmy do ulepszeń poziomu optymalizacji z A77. Nie wspominając o tym, rzućmy okiem na nowości w Arm Cortex-A77.
Cortex-A77 opiera się na mikroarchitekturze A76
Kluczem do zrozumienia różnicy między Cortex-A77 i A76 jest zrozumienie, co oznacza „szerszy” rdzeń. Zasadniczo mówimy o możliwości wykonywania większej liczby instrukcji dla każdego cyklu zegarowego, co zwiększa przepustowość rdzenia. Są dwa ważne elementy, aby to zrobić - zwiększenie liczby jednostek wykonawczych do przetwarzania i zapewnienie, że jednostki te są dobrze karmione danymi. Zacznijmy od drugiej części i skupmy się na częściach SoC w części dotyczącej wysyłki, pamięci podręcznej i predykcji gałęzi.
Cortex-A77 widzi 50-procentowy wzrost szerokości wysyłki, do sześciu instrukcji na cykl z czterech z A76. Oznacza to, że więcej instrukcji kieruje się do rdzenia wykonawczego dla każdego cyklu zegara w celu zwiększenia potencjału wydajności. W wyniku tego okno wykonania poza kolejnością jest również większe, zwiększając się do 160 pozycji, aby ujawnić większą równoległość. Znany jest bufor podręczny instrukcji 64 KB, podczas gdy bufor docelowy rozgałęzienia (BTB), który przechowuje adresy dla predyktora rozgałęzienia, jest o 33 procent większy niż wcześniej, aby obsłużyć wzrost instrukcji równoległych. Nie ma w tym nic niezwykłego, jest to zasadniczo szersza wersja zeszłorocznego projektu.
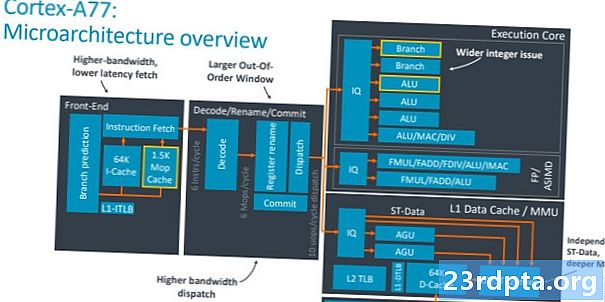
Bardziej intrygującym dodatkiem jest całkowicie nowa pamięć podręczna MOP 1,5 KB, która przechowuje makrooperacje (MOP), które są dostarczane z jednostki dekodującej. Architektura procesora Arm arm dekoduje instrukcje z aplikacji użytkownika do mniejszych makropoleceń, a następnie do mikrooperacji, które rozumie rdzeń wykonawczy. Możesz to zobaczyć na powyższym schemacie w sekcji dekodowania. Pamięć podręczna MOP służy do zmniejszenia kosztu kosztu nieodebranych gałęzi i rzutów, ponieważ trzymasz makropolecenia, a nie dekodujesz je ponownie, i zwiększa ogólną przepustowość rdzenia. Pobierane z MOP zamiast i-cache omijają etap dekodowania, oszczędzając jeden cykl. Arm stwierdza, że pamięć podręczna MOP może osiągnąć 85% lub więcej trafień w zakresie obciążeń, co czyni go bardzo przydatnym dodatkiem do standardowej pamięci podręcznej i-cache.
Przechodząc do głównej części procesora CPU, zwróć uwagę na dodanie czwartej jednostki ALU i drugiej jednostki gałęzi. Ta czwarta jednostka ALU zwiększa ogólną przepustowość procesora o 50 procent. Ta dodatkowa jednostka ALU jest zdolna do wykonywania podstawowych instrukcji jednocyklowych (takich jak ADD i SUB) oraz dwucyfrowych operacji na liczbach całkowitych, takich jak mnożenie. Dwie pozostałe jednostki ALU mogą obsługiwać tylko podstawowe instrukcje jednego cyklu, podczas gdy ostatnia jednostka jest obciążona bardziej zaawansowanymi operacjami matematycznymi, takimi jak dzielenie, mnożenie, akumulacja itp. Druga jednostka rozgałęzienia w rdzeniu wykonawczym podwaja liczbę jednoczesnych skoków rozgałęzień rdzeń może obsłużyć, co jest przydatne w przypadkach, gdy dwie z sześciu wysłanych instrukcji są skokami gałęzi. Brzmi to trochę dziwnie, ale wewnętrzne testy w Arm wykazały korzyści płynące z przyjęcia tej drugiej jednostki.
Cortex-A77 oferuje lepszą równoległość i nowe podejście do pamięci podręcznych pobierania z wyprzedzeniem
Inne poprawki w rdzeniu procesora obejmują dodanie drugiego potoku szyfrowania AES. Rurociągi magazynów danych są teraz wyposażone w dedykowane porty problemów, aby podwoić przepustowość problemu pamięci. Porty te były wcześniej współużytkowane przez ALU, co czasami może stać się wąskim gardłem. Istnieje również narzędzie do doskonalenia danych nowej generacji, które poprawia wydajność energetyczną, a jednocześnie zwiększa przepustowość do systemowej pamięci DRAM.
Część tego systemu w Cortex-A77 zawiera również zupełnie nowy system pobierania wstępnego „uwzględniający system”. Poprawia to wydajność pamięci w oparciu o szeroki zakres liczby rdzeni procesora, pojemności i opóźnień pamięci podręcznej oraz konfiguracji podsystemu pamięci w urządzeniach końcowych. Dedykowany sprzęt do rozmów z jednostką Dynamic Scheduling Unit (DSU) w ramach klastra procesora DynamIQ, który monitoruje użycie wspólnej pamięci podręcznej L3. Rdzeń cechuje się dynamiczną odległością i poziomem agresywności, aby zmniejszyć wykorzystanie pamięci podręcznej w sytuacjach, w których przepustowość L3 jest ograniczona przez inne rdzenie procesora. Rdzenie o wyższej wydajności, takie jak Cortex-A77, częściej nasycają dostęp DSU do pamięci, podczas gdy rdzenie o niższej mocy, takie jak A55, raczej nie będą.

Wszystko razem dopasowane
Istnieje wiele małych zmian w Cortex-A77, które sumują się z pewnymi istotnymi różnicami w stosunku do jego poprzednika. W skrócie, nowa pamięć podręczna MOP A77 w połączeniu z szerszym i dłuższym oknem instrukcji pomaga utrzymać rozbudowane jednostki ALU, rozgałęzienia i jednostki pamięci zajęte czynnościami. Potężny projekt Cortex-A76 został rozszerzony, aby jeszcze bardziej zwiększyć wydajność dzięki A77, bez polegania na wyższych częstotliwościach zegara.
Największe zwiększenie wydajności Cortex-A77 pojawia się w postaci liczb całkowitych i zmiennoprzecinkowych. Potwierdzają to wewnętrzne testy porównawcze Arm, które pokazują wzrost wydajności o 20 do 35 procent odpowiednio w testach całkowitych i zmiennoprzecinkowych SPEC. Poprawa przepustowości pamięci mieści się w przedziale od 15 do 20 procent, ponownie podkreślając, że największe zyski przynoszą skurcze liczb. Ogólnie rzecz biorąc, te ulepszenia dają A77 średnio 20 procentowy wzrost w stosunku do poprzedniej generacji. Możemy również zaobserwować dalsze, bardziej marginalne zyski w wyniku bardziej zaawansowanych procesów produkcyjnych 7 nm jeszcze w tym roku lub na początku 2020 r.
Jeśli chodzi o smartfony, SoC zasilane Cortex-A77 są przeznaczone do flagowych produktów o wysokiej wydajności. Arm w pełni spodziewa się, że w projekcie powerhouse wykorzystany zostanie układ 4 + 4-bitowy. Biorąc pod uwagę zwiększoną przepustowość i niewielki wzrost powierzchni A77, prawdopodobnie zobaczymy, że projektanci SoC kontynuują trend 1 + 3 + 4 lub 2 + 2 + 4. Z jednym lub dwoma mocnymi dużymi rdzeniami z większymi pamięciami podręcznymi i wyższymi zegarami, wspieranymi przez 2 lub 3 rdzenie A77 o mniejszych rozmiarach pamięci podręcznej i niższych zegarach, aby zaoszczędzić energię i powierzchnię. Ostatecznie Cortex-A77 oznacza dobre rzeczy dla układów smartfonów i rosnącego rynku dla zawsze podłączonych laptopów opartych na Arm. Wypatruj silikonowych ogłoszeń jeszcze w tym roku.


