
Zawartość
- Poznaj Google Learning Machine Kit
- Jak korzystać z interfejsów API ML Kit?
- Zidentyfikuj tekst na dowolnym obrazie za pomocą interfejsu API rozpoznawania tekstu
- Zrozumienie treści obrazu: interfejs API do etykietowania obrazów
- Zrozumienie wyrażeń i śledzenie twarzy: interfejs API wykrywania twarzy
- Skanowanie kodów kreskowych za pomocą Firebase i ML
- Uczenie maszynowe w chmurze: interfejs API rozpoznawania punktów orientacyjnych
- Language Identification API: Opracowanie dla międzynarodowej publiczności
- Już wkrótce: inteligentna odpowiedź
- Co dalej? Korzystanie z TensorFlow Lite z ML Kit
- Podsumowując

Uczenie maszynowe (ML) może pomóc w tworzeniu innowacyjnych, atrakcyjnych i unikalnych doświadczeń dla użytkowników mobilnych.
Po opanowaniu ML możesz używać go do tworzenia szerokiej gamy aplikacji, w tym aplikacji, które automatycznie organizują zdjęcia na podstawie ich tematyki, identyfikują i śledzą twarz osoby na żywo, wydobywają tekst z obrazu i wiele więcej .
Ale ML nie jest specjalnie przyjazny dla początkujących! Jeśli chcesz rozszerzyć swoje aplikacje na Androida o potężne możliwości uczenia maszynowego, od czego dokładnie zaczynasz?
W tym artykule przedstawię przegląd zestawu SDK (Software Development Kit), który obiecuje udostępnić moc ML na wyciągnięcie ręki, nawet jeśli masz zero Doświadczenie ML. Pod koniec tego artykułu będziesz mieć podstawy do tworzenia inteligentnych aplikacji opartych na ML, które mogą oznaczać obrazy, skanować kody kreskowe, rozpoznawać twarze i słynne punkty orientacyjne oraz wykonywać wiele innych potężnych zadań ML.
Poznaj Google Learning Machine Kit
Wraz z wydaniem technologii takich jak TensorFlow i CloudVision, ML staje się coraz bardziej rozpowszechniony, ale te technologie nie są dla osób o słabym sercu! Zwykle potrzebujesz głębokiego zrozumienia sieci neuronowych i analizy danych rozpoczęła się z technologią taką jak TensorFlow.
Nawet jeśli ty robić masz pewne doświadczenie z ML, tworzenie aplikacji mobilnej opartej na uczeniu maszynowym może być czasochłonnym, złożonym i kosztownym procesem, wymagającym od Ciebie uzyskania wystarczającej ilości danych do przeszkolenia własnych modeli ML, a następnie zoptymalizowania tych modeli ML, aby działały wydajnie środowisko mobilne. Jeśli jesteś indywidualnym programistą lub masz ograniczone zasoby, może nie być możliwe wykorzystanie wiedzy ML w praktyce.
ML Kit to próba Google'a wprowadzenia masowego uczenia się.
Pod maską ML Kit łączy kilka potężnych technologii ML, które zwykle wymagają obszernej wiedzy na temat ML, w tym Cloud Vision, TensorFlow i interfejs API sieci neuronowych Androida. ML Kit łączy te specjalistyczne technologie ML ze wstępnie przeszkolonymi modelami do typowych zastosowań mobilnych, w tym wyodrębnianie tekstu z obrazu, skanowanie kodu kreskowego i identyfikowanie zawartości zdjęcia.
Bez względu na to, czy masz jakąkolwiek wcześniejszą wiedzę na temat ML, możesz użyć ML Kit, aby dodać potężne możliwości uczenia maszynowego do swojego Androida i Aplikacje na iOS - po prostu przekaż niektóre dane do właściwej części ML Kit, takiej jak Text Recognition lub Language Identification API, a ten interfejs API użyje uczenia maszynowego do zwrócenia odpowiedzi.
Jak korzystać z interfejsów API ML Kit?
ML Kit jest podzielony na kilka interfejsów API, które są dystrybuowane jako część platformy Firebase. Aby korzystać z dowolnego interfejsu API ML Kit, musisz utworzyć połączenie między projektem Android Studio a odpowiednim projektem Firebase, a następnie nawiązać połączenie z Firebase.
Większość modeli ML Kit jest dostępnych jako modele na urządzeniu, które można pobrać i używać lokalnie, ale niektóre modele są również dostępne w chmurze, co pozwala Twojej aplikacji na wykonywanie zadań opartych na ML przez połączenie internetowe urządzenia.
Każde podejście ma swój unikalny zestaw mocnych i słabych stron, więc musisz zdecydować, czy przetwarzanie lokalne lub zdalne jest najbardziej odpowiednie dla konkretnej aplikacji. Możesz nawet dodać obsługę obu modeli, a następnie pozwolić użytkownikom decydować, którego modelu użyć w czasie wykonywania. Alternatywnie możesz skonfigurować aplikację tak, aby wybierała najlepszy model dla bieżących warunków, na przykład używając modelu w chmurze tylko wtedy, gdy urządzenie jest podłączone do Wi-Fi.
Jeśli wybierzesz model lokalny, funkcje uczenia maszynowego Twojej aplikacji będą zawsze dostępne, niezależnie od tego, czy użytkownik ma aktywne połączenie z Internetem. Ponieważ cała praca jest wykonywana lokalnie, modele na urządzeniu są idealne, gdy aplikacja musi szybko przetwarzać duże ilości danych, na przykład jeśli używasz ML Kit do manipulowania strumieniem wideo na żywo.
Tymczasem modele oparte na chmurze zazwyczaj zapewniają większą dokładność niż ich odpowiedniki na urządzeniach, ponieważ modele w chmurze wykorzystują moc technologii uczenia maszynowego Google Cloud Platform. Na przykład model urządzenia Image Labeling API na urządzeniu zawiera 400 etykiet, ale model chmury jest już dostępny 10 000 etykiet.
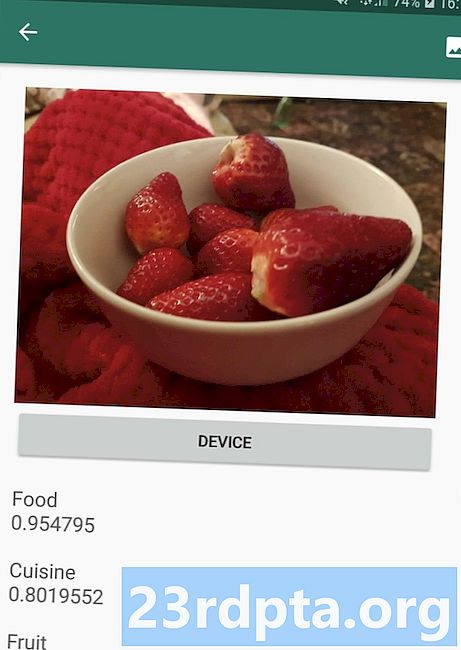
W zależności od interfejsu API niektóre funkcje mogą być dostępne tylko w chmurze, na przykład interfejs API rozpoznawania tekstu może identyfikować znaki spoza alfabetu łacińskiego, jeśli użyjesz jego modelu opartego na chmurze.
Interfejsy API oparte na chmurze są dostępne tylko dla projektów Firebase na poziomie Blaze, więc musisz uaktualnić do planu Blaze zgodnie z rzeczywistym użyciem, zanim będziesz mógł używać dowolnego modelu chmury ML Kit.
Jeśli zdecydujesz się na eksplorację modeli chmurowych, w momencie pisania tego tekstu dostępna była bezpłatna przydział dla wszystkich interfejsów API ML Kit. Jeśli chcesz po prostu eksperymentować z chmurowym znakowaniem obrazów, możesz uaktualnić swój projekt Firebase do planu Blaze, przetestować API na mniej niż 1000 obrazów, a następnie przełączyć się z powrotem na bezpłatny plan Spark, bez opłat. Jednak warunki zmieniają się z czasem, więc przed przejściem na Blaze zapoznaj się z drobnym drukiem, aby uniknąć niespodziewanych rachunków!
Zidentyfikuj tekst na dowolnym obrazie za pomocą interfejsu API rozpoznawania tekstu
Interfejs API rozpoznawania tekstu może inteligentnie identyfikować, analizować i przetwarzać tekst.
Możesz użyć tego interfejsu API do tworzenia aplikacji, które wyodrębniają tekst z obrazu, aby użytkownicy nie musieli tracić czasu na żmudne ręczne wprowadzanie danych. Na przykład możesz użyć interfejsu API rozpoznawania tekstu, aby pomóc użytkownikom wydobywać i rejestrować informacje z paragonów, faktur, wizytówek, a nawet etykiet żywieniowych, po prostu robiąc zdjęcie danego produktu.

Możesz nawet użyć interfejsu API rozpoznawania tekstu jako pierwszego kroku w aplikacji tłumaczeniowej, w której użytkownik robi zdjęcie nieznanego tekstu, a interfejs API wyodrębnia cały tekst z obrazu, gotowy do przekazania do usługi tłumaczeniowej.
Interfejs API rozpoznawania tekstu na urządzeniu ML Kit może identyfikować tekst w dowolnym języku łacińskim, a jego odpowiednik w chmurze rozpoznaje większą różnorodność języków i znaków, w tym znaki chińskie, japońskie i koreańskie. Model oparty na chmurze jest również zoptymalizowany do wyodrębniania rzadkiego tekstu z obrazów i tekstu z gęsto spakowanych dokumentów, co należy wziąć pod uwagę przy podejmowaniu decyzji, który model zastosować w aplikacji.
Chcesz mieć praktyczne doświadczenie z tym interfejsem API? Następnie zapoznaj się z naszym przewodnikiem krok po kroku dotyczącym tworzenia aplikacji, która może wyodrębnić tekst z dowolnego obrazu za pomocą interfejsu API rozpoznawania tekstu.
Zrozumienie treści obrazu: interfejs API do etykietowania obrazów
Interfejs API etykietowania obrazów może rozpoznawać byty na obrazie, w tym lokalizacje, ludzi, produkty i zwierzęta, bez potrzeby stosowania dodatkowych metadanych kontekstowych. Interfejs API etykietowania obrazów zwróci informacje o wykrytych elementach w postaci etykiet. Na przykład na poniższym zrzucie ekranu podałem interfejsowi API zdjęcie natury, na które odpowiedziałem etykietami „Las” i „Rzeka”.
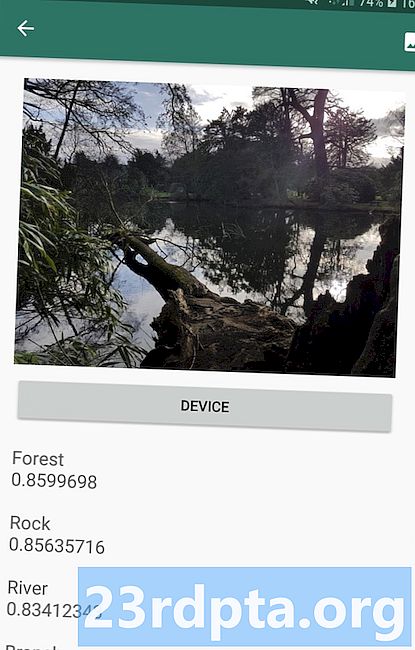
Ta zdolność rozpoznawania zawartości obrazu może pomóc w tworzeniu aplikacji, które oznaczają zdjęcia na podstawie ich tematyki; filtry, które automatycznie identyfikują nieodpowiednie treści przesłane przez użytkowników i usuwają je z aplikacji; lub jako podstawa zaawansowanej funkcji wyszukiwania.
Wiele interfejsów API ML Kit zwraca wiele możliwych wyników, wraz z towarzyszącymi im wynikami ufności - w tym API do etykietowania obrazów. Jeśli zdasz Etykietowanie zdjęcia pudla, może zwrócić etykiety, takie jak „pudel”, „pies”, „zwierzę domowe” i „małe zwierzę”, wszystkie ze zmiennymi wynikami wskazującymi zaufanie API do każdej etykiety. Mamy nadzieję, że w tym scenariuszu „pudel” będzie miał najwyższy wynik zaufania!
Możesz użyć tego wyniku ufności, aby stworzyć próg, który należy spełnić, zanim aplikacja zacznie działać na określonej etykiecie, na przykład wyświetlając ją użytkownikowi lub oznaczając zdjęcie tą etykietą.
Etykietowanie obrazów jest dostępne zarówno na urządzeniu, jak i w chmurze, ale jeśli wybierzesz model w chmurze, uzyskasz dostęp do ponad 10 000 etykiet, w porównaniu do 400 etykiet zawartych w modelu na urządzeniu.
Aby uzyskać bardziej dogłębne spojrzenie na interfejs API etykietowania obrazów, sprawdź Określanie zawartości obrazu za pomocą uczenia maszynowego. W tym artykule tworzymy aplikację, która przetwarza obraz, a następnie zwraca etykiety i oceny ufności dla każdej jednostki wykrytej w tym obrazie. W tej aplikacji wdrażamy również modele na urządzeniu i w chmurze, dzięki czemu możesz dokładnie zobaczyć, jak różnią się wyniki, w zależności od wybranego modelu.
Zrozumienie wyrażeń i śledzenie twarzy: interfejs API wykrywania twarzy
Interfejs API wykrywania twarzy może lokalizować ludzkie twarze na zdjęciach, filmach i transmisjach na żywo, a następnie wyodrębnia informacje o każdej wykrytej twarzy, w tym jej pozycję, rozmiar i orientację.
Możesz użyć tego interfejsu API, aby pomóc użytkownikom w edytowaniu ich zdjęć, na przykład poprzez automatyczne przycięcie całej pustej przestrzeni wokół ich najnowszego zdjęcia.
Interfejs API wykrywania twarzy nie jest ograniczony do obrazów - możesz również zastosować ten interfejs API do filmów, na przykład możesz utworzyć aplikację, która identyfikuje wszystkie twarze w kanale wideo, a następnie wszystko rozmywa z wyjątkiem te twarze, podobne do funkcji rozmycia tła w Skypie.
Wykrywanie twarzy to zawsze wykonywane na urządzeniu, gdzie jest wystarczająco szybkie, aby można było z niego korzystać w czasie rzeczywistym, więc w przeciwieństwie do większości interfejsów API ML Kit, wykrywanie twarzy nie uwzględnij model chmurowy.
Oprócz wykrywania twarzy ten interfejs API ma kilka dodatkowych funkcji, które warto poznać. Po pierwsze, interfejs API wykrywania twarzy może identyfikować punkty orientacyjne twarzy, takie jak oczy, usta i uszy, a następnie pobiera dokładne współrzędne dla każdego z tych punktów orientacyjnych. To rozpoznawanie punktów orientacyjnych zapewnia dokładną mapę każdej wykrytej twarzy - idealną do tworzenia aplikacji rozszerzonej rzeczywistości (AR), które dodają maski i filtry w stylu Snapchata do kanału kamery użytkownika.
Interfejs API wykrywania twarzy oferuje również funkcje twarzy Klasyfikacja. Obecnie ML Kit obsługuje dwie klasyfikacje twarzy: oczy otwarte i uśmiechnięte.

Możesz użyć tej klasyfikacji jako podstawy usług ułatwień dostępu, takich jak sterowanie zestawem głośnomówiącym, lub do tworzenia gier, które reagują na mimikę gracza. Możliwość wykrycia, czy ktoś się uśmiecha lub ma otwarte oczy, może być również przydatna, jeśli tworzysz aplikację aparatu - w końcu nie ma nic gorszego niż robienie wielu zdjęć, tylko po to, aby później odkryć, że ktoś miał zamknięte oczy w każdy strzał.
Wreszcie interfejs API wykrywania twarzy zawiera komponent śledzenia twarzy, który przypisuje identyfikator do twarzy, a następnie śledzi tę twarz na wielu kolejnych obrazach lub ramkach wideo. Zauważ, że to jest twarz śledzenie i nie jest to prawdziwa twarz uznanie. Za kulisami API wykrywania twarzy śledzi pozycję i ruch twarzy, a następnie wnioskuje, że ta twarz prawdopodobnie należy do tej samej osoby, ale ostatecznie nie jest świadoma tożsamości tej osoby.
Wypróbuj interfejs API wykrywania twarzy! Dowiedz się, jak zbudować aplikację do wykrywania twarzy za pomocą uczenia maszynowego i Firebase ML Kit.
Skanowanie kodów kreskowych za pomocą Firebase i ML
Skanowanie kodów kreskowych może nie wydawać się tak ekscytujące, jak niektóre inne interfejsy API uczenia maszynowego, ale jest to jedna z najbardziej dostępnych części ML Kit.
Skanowanie kodu kreskowego nie wymaga żadnego specjalistycznego sprzętu ani oprogramowania, więc możesz korzystać z interfejsu API do skanowania kodów kreskowych, jednocześnie upewniając się, że Twoja aplikacja jest dostępna dla jak największej liczby osób, w tym użytkowników starszych lub budżetowych urządzeń. Tak długo, jak urządzenie ma działającą kamerę, nie powinno mieć problemów ze skanowaniem kodu kreskowego.
Interfejs API do skanowania kodów kreskowych ML Kit może wydobywać szeroki zakres informacji z drukowanych i cyfrowych kodów kreskowych, co sprawia, że jest to szybki, łatwy i dostępny sposób przekazywania informacji ze świata rzeczywistego do Twojej aplikacji, bez konieczności wykonywania przez użytkownika żmudnego ręcznego wprowadzania danych .
Istnieje dziewięć różnych typów danych, które interfejs API do skanowania kodów kreskowych może rozpoznać i przeanalizować z kodu kreskowego:
- TYPE_CALENDAR_EVENT. Zawiera informacje takie jak lokalizacja wydarzenia, organizator oraz czas rozpoczęcia i zakończenia.Jeśli promujesz wydarzenie, możesz dołączyć wydrukowany kod kreskowy na swoich plakatach lub ulotkach lub polecić cyfrowy kod kreskowy na swojej stronie. Potencjalni uczestnicy mogą następnie wyodrębnić wszystkie informacje o wydarzeniu, po prostu skanując jego kod kreskowy.
- TYPE_CONTACT_INFO. Ten typ danych obejmuje takie informacje, jak adres e-mail kontaktu, imię i nazwisko, numer telefonu oraz tytuł.
- TYPE_DRIVER_LICENSE. Zawiera informacje takie jak ulica, miasto, stan, imię i data urodzenia związane z prawem jazdy.
- TYPE_EMAIL. Ten typ danych obejmuje adres e-mail, temat wiadomości e-mail i treść.
- TYPE_GEO. Zawiera szerokość i długość geograficzną dla określonego punktu geograficznego, co jest łatwym sposobem na udostępnianie lokalizacji użytkownikom lub dzielenie się nimi z innymi. Możesz nawet potencjalnie użyć kodów kreskowych geograficznych do wyzwalania zdarzeń związanych z lokalizacją, takich jak wyświetlanie niektórych przydatnych informacji o bieżącej lokalizacji użytkownika lub jako podstawa gier mobilnych opartych na lokalizacji.
- TYPE_PHONE. Zawiera numer telefonu i typ numeru, na przykład, czy jest to numer służbowy czy domowy.
- TYPE_SMS. Zawiera on treść SMS-a i numer telefonu powiązany z SMS-em.
- TYPE_URL. Ten typ danych zawiera adres URL i jego tytuł. Skanowanie kodu kreskowego TYPE_URL jest znacznie łatwiejsze niż poleganie na ręcznym wpisywaniu długiego, złożonego adresu URL bez popełniania literówek i błędów ortograficznych.
- TYPE_WIFI. Zawiera identyfikator SSID i hasło sieci Wi-Fi, a także jej typ szyfrowania, taki jak OPEN, WEP lub WPA. Kod kreskowy Wi-Fi jest jednym z najłatwiejszych sposobów udostępniania poświadczeń Wi-Fi, jednocześnie całkowicie eliminując ryzyko niepoprawnego wprowadzenia tych informacji przez użytkowników.
Interfejs API do skanowania kodów kreskowych może analizować dane z szeregu różnych kodów kreskowych, w tym formatów liniowych, takich jak Codabar, Code 39, EAN-8, ITF i UPC-A, oraz formatów 2D, takich jak Aztec, Data Matrix i kody QR.
Aby ułatwić użytkownikom końcowym, ten interfejs API skanuje jednocześnie wszystkie obsługiwane kody kreskowe, a także może wyodrębniać dane niezależnie od orientacji kodu kreskowego - więc nie ma znaczenia, czy kod kreskowy jest całkowicie odwrócony, gdy użytkownik go skanuje!
Uczenie maszynowe w chmurze: interfejs API rozpoznawania punktów orientacyjnych
Możesz użyć interfejsu API rozpoznawania punktów orientacyjnych ML Kit, aby zidentyfikować znane naturalne i zbudowane punkty orientacyjne na obrazie.
Jeśli przekażesz temu API obraz zawierający słynny punkt orientacyjny, zwróci nazwę tego punktu orientacyjnego, wartości szerokości i długości geograficznej punktu orientacyjnego oraz ramkę ograniczającą wskazującą, gdzie punkt orientacyjny został odkryty na obrazie.
Możesz użyć interfejsu Landmark Recognition API do tworzenia aplikacji, które automatycznie tagują zdjęcia użytkownika lub w celu zapewnienia bardziej spersonalizowanego doświadczenia, na przykład jeśli Twoja aplikacja rozpozna, że użytkownik robi zdjęcia z Wieży Eiffla, może zaoferować kilka interesujących faktów na temat ten punkt orientacyjny lub sugeruj podobne pobliskie atrakcje turystyczne, które użytkownik może chcieć odwiedzić w następnej kolejności.
Niezwykle w przypadku ML Kit Landmark Detection API jest dostępny tylko jako oparty na chmurze interfejs API, więc aplikacja będzie mogła wykrywać punkty orientacyjne tylko wtedy, gdy urządzenie ma aktywne połączenie z Internetem.
Language Identification API: Opracowanie dla międzynarodowej publiczności
Obecnie aplikacje na Androida są używane w każdej części świata przez użytkowników mówiących w wielu różnych językach.
Interfejs API identyfikacji języka ML Kit może pomóc Twojej aplikacji na Androida przyciągnąć międzynarodową publiczność, pobierając ciąg tekstu i określając język, w którym jest napisany. Interfejs API identyfikacji języka może identyfikować ponad sto różnych języków, w tym tekst romanizowany w języku arabskim, bułgarskim, Chiński, grecki, hindi, japoński i rosyjski.
Ten interfejs API może być cennym dodatkiem do każdej aplikacji przetwarzającej tekst dostarczony przez użytkownika, ponieważ tekst ten rzadko zawiera informacje o języku. Możesz również użyć interfejsu API do identyfikacji języka w aplikacjach tłumaczeniowych, jako pierwszego kroku do tłumaczenia byle co, wie, z jakim językiem współpracujesz! Na przykład, jeśli użytkownik skieruje kamerę swojego urządzenia na menu, wówczas aplikacja może użyć interfejsu API do identyfikacji języka w celu ustalenia, czy menu jest napisane w języku francuskim, a następnie zaoferować tłumaczenie tego menu za pomocą usługi takiej jak Cloud Translation API ( być może po wypakowaniu tekstu za pomocą interfejsu API rozpoznawania tekstu?)
W zależności od łańcucha, o którym mowa, interfejs API identyfikacji języka może zwracać wiele potencjalnych języków, którym towarzyszą oceny ufności, abyś mógł określić, który wykryty język najprawdopodobniej będzie poprawny. Pamiętaj, że w momencie pisania ML Kit nie mógł zidentyfikować wielu różnych języków w tym samym ciągu.
Aby zapewnić, że ten interfejs API zapewnia identyfikację języka w czasie rzeczywistym, interfejs API identyfikacji języka jest dostępny tylko jako model na urządzeniu.
Już wkrótce: inteligentna odpowiedź
Google planuje dodać więcej interfejsów API do ML Kit w przyszłości, ale wiemy już o jednym nadchodzącym interfejsie API.
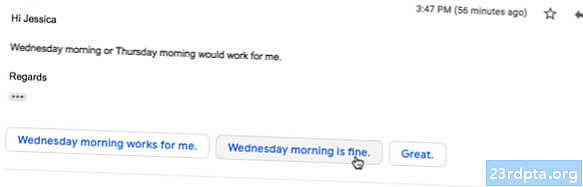
Według strony internetowej ML Kit, nadchodzące Inteligentny interfejs API odpowiedzi pozwoli Ci oferować kontekstowe odpowiedzi na wiadomości w twoich aplikacjach, sugerując fragmenty tekstu pasujące do bieżącego kontekstu. Na podstawie tego, co już wiemy o tym interfejsie API, wydaje się, że Smart Reply będzie podobny do funkcji sugerowanej odpowiedzi dostępnej już w aplikacji na Androida, Wear OS i Gmailu.
Poniższy zrzut ekranu pokazuje, jak obecnie wygląda funkcja sugerowanej odpowiedzi w Gmailu.
Co dalej? Korzystanie z TensorFlow Lite z ML Kit
ML Kit zapewnia gotowe modele do powszechnych mobilnych zastosowań, ale w pewnym momencie możesz chcieć wyjść poza te gotowe modele.
Możliwe jest tworzenie własnych modeli ML za pomocą TensorFlow Lite, a następnie rozpowszechnianie ich za pomocą ML Kit. Należy jednak pamiętać, że w przeciwieństwie do gotowych interfejsów API ML Kit, praca z własnymi modelami ML wymaga znaczący ilość wiedzy specjalistycznej ML.
Po utworzeniu modeli TensorFlow Lite możesz przesłać je do Firebase, a Google będzie zarządzać hostingiem i udostępnianiem tych modeli użytkownikom końcowym. W tym scenariuszu ML Kit działa jako warstwa API nad modelem niestandardowym, co upraszcza niektóre z ciężkich zadań związanych z używaniem modeli niestandardowych. Co najważniejsze, ML Kit automatycznie przesyła użytkownikom najnowszą wersję Twojego modelu, więc nie musisz aktualizować aplikacji za każdym razem, gdy chcesz ulepszyć swój model.
Aby zapewnić najlepszą możliwą obsługę, możesz określić warunki, które muszą zostać spełnione, zanim aplikacja pobierze nowe wersje modelu TensorFlow Lite, na przykład aktualizując model tylko, gdy urządzenie jest w stanie bezczynności, jest ładowane lub podłączone do Wi- Fi. Możesz nawet używać ML Kit i TensorFlow Lite wraz z innymi usługami Firebase, na przykład używając Firebase Remote Config i Firebase A / B Testing, aby obsługiwać różne modele dla różnych zestawów użytkowników.
Jeśli chcesz wyjść poza modele wcześniej zbudowane lub istniejące modele ML Kit nie spełniają Twoich potrzeb, możesz dowiedzieć się więcej o tworzeniu własnych modeli uczenia maszynowego w oficjalnych dokumentach Firebase.
Podsumowując
W tym artykule przyjrzeliśmy się każdemu składnikowi zestawu uczenia maszynowego Google i omówiliśmy kilka typowych scenariuszy, w których możesz chcieć użyć każdego interfejsu API zestawu ML.
Google planuje dodać więcej interfejsów API w przyszłości, więc które interfejsy API do uczenia maszynowego chcesz dodać do ML Kit? Daj nam znać w komentarzach poniżej!
")

